最後更新: 2026年3月26日
你會讓同一個工程師自己寫、自己測、自己 review 再自己上線嗎?
Anthropic 的新文章讓我更確定,AI agent 也需要分工。很多人類團隊踩過的坑,AI 會重新踩一次。
TL;DR
先看重點
>同一個 AI agent 同時負責 planning、generation、review 和 deployment,通常就像讓同一個人包辦整個團隊。
>AI 團隊的分工問題,本質上和人類團隊很像,差別只在速度更快、錯誤放大也更快。
>這篇文章的重點是 role separation 與 orchestration,不是多 agent 比單 agent 更炫。
#讓工作輕鬆一點 你會讓同一個工程師自己寫 code、自己測試、自己 review 然後自己上線嗎?
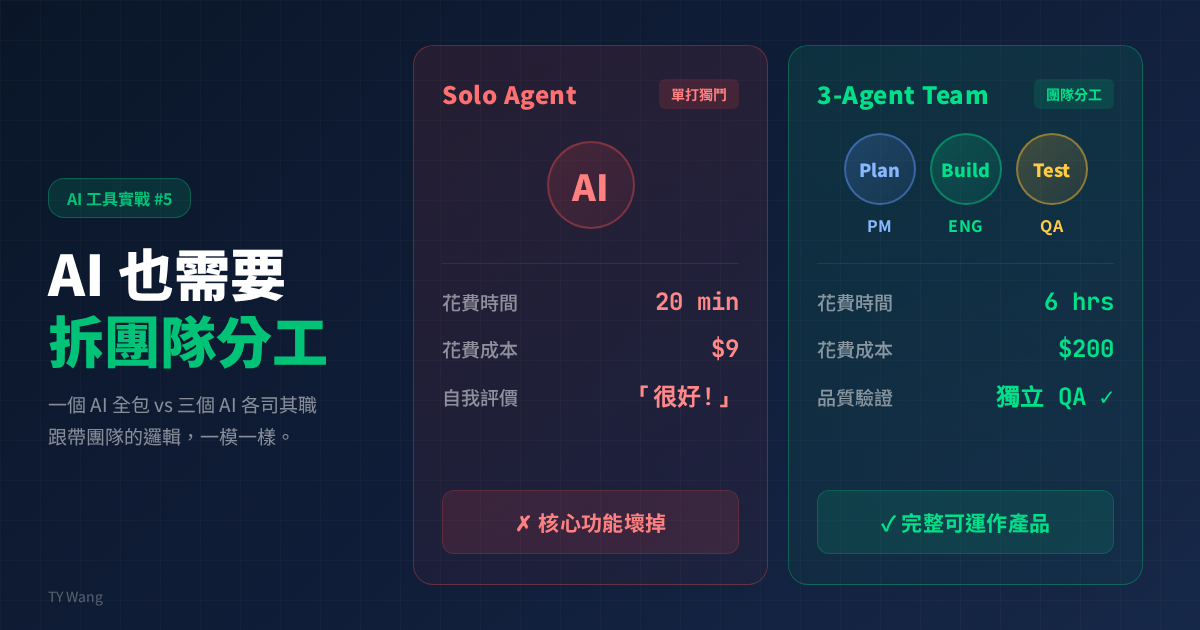
不會吧。但我們每天都在讓 AI 做這件事。
Anthropic 最近發了一篇技術文章,講他們怎麼讓 Claude 從零開始做出完整的應用程式。結論很有意思:一個 AI 做不好的事,拆成三個 AI 之後,反而做得比較像樣。
這跟我們帶團隊的邏輯,其實非常像。
1. 一人包辦的問題
他們先做了一個很直覺的嘗試:讓單一 AI 從頭包到尾,規劃、寫 code、測試、修 bug 全部自己來。
結果出現兩個問題:
- context 一滿,AI 開始焦慮,會趕著收尾,品質往下掉
- 讓它自己 review 自己的東西,它很容易高估自己的表現
Anthropic 原文說法是 inflated self-assessment。說白了,就是 AI 也會自我感覺良好。
2. 從 GAN 借來的靈感
他們後來的做法,是把「做事的」跟「挑毛病的」拆開。
最後整個系統分成三個 agent:
Planner:像 PM,負責把模糊需求展成完整 specGenerator:像工程師,分 sprint 去逐步做功能Evaluator:像 QA,用 Playwright 真的去操作 app、找 bug
而且 Generator 和 Evaluator 在動手前還會先定義好一輪 sprint 的成功標準。這整件事聽起來是不是很像 sprint planning?因為本質上就是。
3. 數據很誠實
他們拿同一個任務做對比:
- 單一 AI:20 分鐘、9 美金,結果核心功能壞掉
- 三個 AI 分工:6 小時、200 美金,結果產品真的可用
這個成本當然高很多,但換來的是「能用」和「不能用」的差別。另一個 DAW 的案例也很類似,真正抓出問題的是 Evaluator,而不是 Generator 自己。
4. 帶團隊的人看到會很有感
我在 dentall 帶產品事業處的體感是,很多人的團隊管理直覺,其實可以直接拿來看 AI agent 的架構。
- 寫 code 的人不該自己做 QA,因為你一定有盲點
- spec 沒清楚就開工,通常一定爆
- 一個人全包看起來很快,但品質不穩
這些我們在人類團隊裡踩過的坑,AI 只是重新踩一次而已。
5. 支架要記得拆
我很喜歡文章最後一個 insight。
他們一開始因為 Opus 4.5 有明顯的 context 焦慮,所以設計了很多很重的機制去補。後來 Opus 4.6 進步了,這些限制不再那麼明顯,他們就把多餘的支架拆掉。
這個觀念我覺得不只適用於 AI。你的團隊流程、你的管理制度,是不是也有一些是因為以前出過事,所以一路加上去,但現在其實已經不一定需要了?
後記
這篇開始讓我更明確地覺得:AI 的組織方式,本身就會是一個很值得研究的題目。
如果你還把 AI 當成單一工具,可能會低估接下來的變化。很多時候,問題已經不是「模型夠不夠強」,而是「你怎麼安排它工作」。
PS
Anthropic 那篇文章裡有一句話我很喜歡:把 evaluator 訓練成一個很挑剔的角色,比讓 generator 自己批評自己容易太多了。
嗯,這大概也是為什麼公司會有 QA,而不是讓工程師自己說「我測過了,應該沒問題」。


