Last updated: March 26, 2026
Would you let the same engineer code, test, review, and deploy alone?
Anthropic's new article made me more certain that AI agents also need role separation. A lot of team lessons get repeated almost exactly.
TL;DR
Key takeaways first
>When one AI agent is asked to plan, generate, review, and deploy, it often recreates the same coordination problems human teams already learned the hard way.
>Role separation matters because AI systems can compound mistakes much faster than human workflows.
>The real point of this article is orchestration and responsibility design, not multi-agent hype.
Would you let the same engineer code, test, review, and deploy alone?
Probably not. But that is basically what we keep asking AI to do.
Anthropic recently published a technical write-up on how they used Claude to build a full application from scratch. What stood out to me was the conclusion: work that looked weak when handled by one AI started looking much better once it was split across three.
That is basically team design logic.
1. The problem with one agent doing everything
Their first instinct was obvious: let one AI do the whole thing. Planning, coding, testing, bug fixing, all in one loop.
Two problems showed up quickly:
- once the context got too full, the model started rushing to finish and quality dropped
- when the model reviewed its own output, it rated itself too generously
Anthropic calls this inflated self-assessment. In more normal language: AI also gets overconfident about its own work.
2. Borrowing the idea from GANs
The fix was to separate the part that builds from the part that criticizes.
Their final system used three agents:
Planner: more like a PM, turning vague requests into a clear specGenerator: more like an engineer, implementing features in sprintsEvaluator: more like QA, using Playwright to actually operate the app and find real problems
The Generator and Evaluator also agree on a sprint contract before work begins. If that sounds familiar, it is because it is very close to sprint planning.
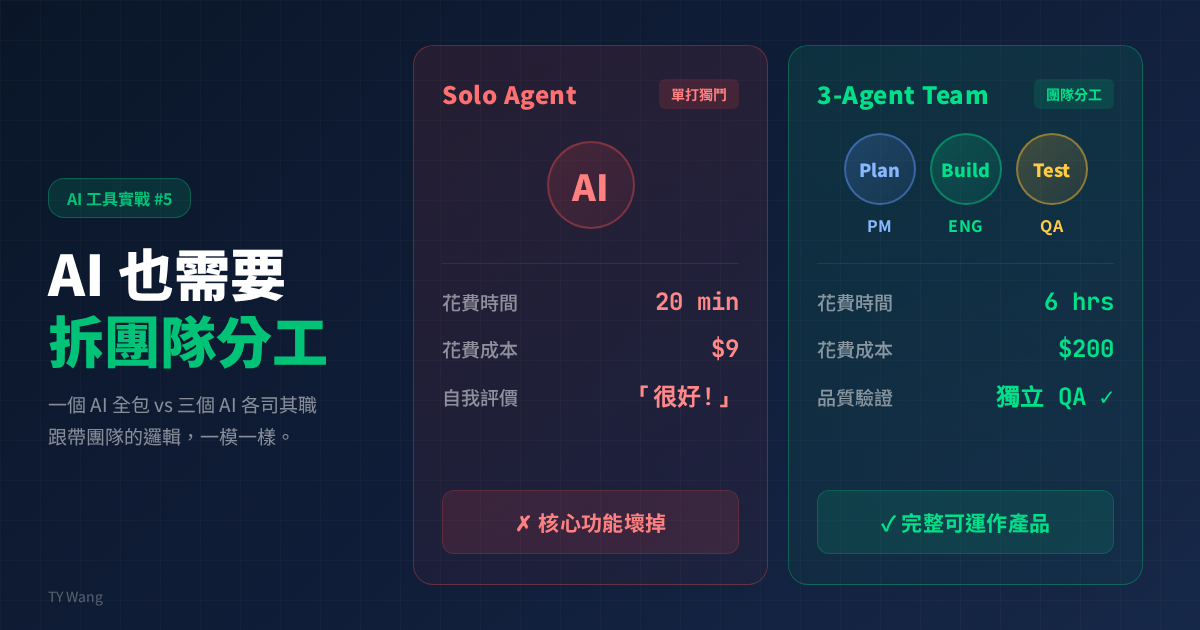
3. The numbers are hard to argue with
They compared the same task in two ways:
- one AI: 20 minutes, $9, but the core feature was broken
- three AIs: 6 hours, $200, but the product actually worked
Yes, the cost is much higher. But the difference is also basically "usable" versus "not usable." In another DAW example, it was the Evaluator that caught the bug, not the Generator reviewing its own work.
4. Anyone who has led a team will recognize this
My experience leading product and engineering at dentall is that a lot of human team-management instinct applies almost directly to AI agent design.
- the person writing code should not also be the only QA
- if the spec is fuzzy, execution usually breaks
- one person doing everything can look efficient, but quality gets unstable
These are not new lessons. AI is just replaying them.
5. You also have to remember to remove scaffolding
One of my favorite parts of the article came near the end.
They built a lot of extra scaffolding because Opus 4.5 had clear context-anxiety behavior. Once Opus 4.6 improved, some of that scaffolding no longer made sense, so they removed it.
That idea applies beyond AI. A lot of team processes and management rules exist because something broke in the past. But once the underlying condition changes, those extra layers may become unnecessary weight.
Closing note
This article pushed me further toward one belief: the way AI is organized is becoming a topic in its own right.
At some point the question stops being "is the model good enough?" and becomes "how are you arranging the work around it?"
PS
One line from the Anthropic piece really stayed with me: it is much easier to train an evaluator to be strict than to ask a generator to be honest about its own work.
Which is probably why companies have QA teams instead of letting engineers say "I tested it, looks fine."


