Last updated: April 22, 2026
GPT-Image-2 finally connects the design-to-code chain
Better images are not the headline. The headline is that the design-to-code pipeline finally holds together — and what that means for how teams are organised.
TL;DR
Key takeaways first
>GPT-Image-2 pushed image generation past a quality threshold that finally lets the design-to-code pipeline hold together end to end.
>The public benchmark jumped from 1,114 to 1,512, with Chinese typography, layout, and detail finally print-ready.
>The organisational impact is bigger than the product impact — image generation can shift earlier, and the team bottleneck moves from 'who draws this' to 'who makes good product calls'.
OpenAI launched GPT-Image-2 today, pushing the quality of AI image generation forward by a noticeable step. But what I find more interesting is not "the images look better." It is that the design-to-code pipeline finally connects end to end — and what that means for how teams will be organised.
1. Claude Design opened the door, GPT-Image-2 fills in the quality
Claude Design becoming a hit over the past week was about showing the world that the design-to-code pipeline can flow: concept → implementable visual mockup → coding agent → product. The idea works. The path is real.
But in practice, one bottleneck on this chain is the quality of the generated images themselves. I have run variants of this workflow several times in the past year, and the conclusion has been similar each time — the layout shows up, but the typography, alignment, Chinese text, and detail precision are not good enough. The agent then sees a noisy reference and gets even more confused. A designer ends up patching it anyway.
The blocker has never been "can it be done." It is "can the output actually be used."
What makes GPT-Image-2 worth revisiting is that the image quality crossed a threshold. With the same prompt, where two or three out of ten outputs used to be usable, now seven or eight come close to production quality. For a pipeline, that is the kind of quantitative shift that becomes qualitative.
2. Almost a 400-point jump on the leaderboard
On the public benchmark, GPT-Image-2 jumped from 1,114 to 1,512 — 242 points ahead of the second-place Google Nano-banana (1,270). That is the largest single jump anyone has made in 2026 so far. Everyone else is still bunched in the 1,100 range — BFL, Tencent, Bytedance, Alibaba.
Benchmarks are not the same as practical usefulness. But when a model creates this size of gap on a public leaderboard, it usually means something real changed in the underlying architecture, not a parameter tweak.
3. Chinese text generation finally crossed the line
If you build Chinese-language interfaces, you know the pattern — past AI image models would produce something that looked confidently like Chinese characters but was structurally garbled. Wrong stroke counts. Broken radicals. Layouts off-axis. For posters, patient education materials, or specs that need precise Chinese, the output was basically scrap.
This release is different. I tested Chinese posters, patient education materials, and tabular UI screens. The typography is correct, the alignment holds, and the quality is print-ready.
4. The design-to-code handoff keeps getting tighter
Talking to teams over the past year about adopting AI coding agents, almost every team gets stuck at the same place — the UI the agent produces is either not visually good enough, or it looks too similar to everyone else's.
This is not the agent being weak. Asking an agent to imagine a UI from scratch is genuinely hard, and even senior frontend humans cannot reliably do it either. The right answer is to give the agent a concrete visual reference. But producing "a visual reference worth referencing" used to require a designer or another tool chain — so the pipeline broke right there.
Now the chain holds together: a PM or engineer prompts a mockup → a coding agent implements against the image → it iterates against the same reference until it matches. People without a design background can get in minutes what used to take a designer two or three days.
To be very clear here — the point is not "replacing designers." Designers were never paid to draw mockups. They were paid for product judgement and taste. The point is that the handoff has fewer broken links every quarter.
A practical workflow that works today:
- Use
GPT-Image-2insideCodexto generate the UI mockup - Ask
Codexto implement the UI against that image - Ask
Codexto iterate against the image until it matches
The whole loop fits inside the Codex app.
5. The organisational impact will outweigh the product impact
I look at this as a founder, so my angle is not "how much better will the product get" but "how much faster can the team move."
The old chain — product → design → dev — was sequential. Each station blocked the next. With image generation moving forward, the design station's first pass can shift earlier: a PM or engineer ships v0, the designer reviews and makes the taste call. The team's bottleneck shifts from "who draws this" to "who makes good product calls."
That is a good thing, but it is also a hard thing — every individual on the team has to operate at a higher abstraction level. People who cannot keep up with the pace will quietly become tied down by their old role definition.
Closing note
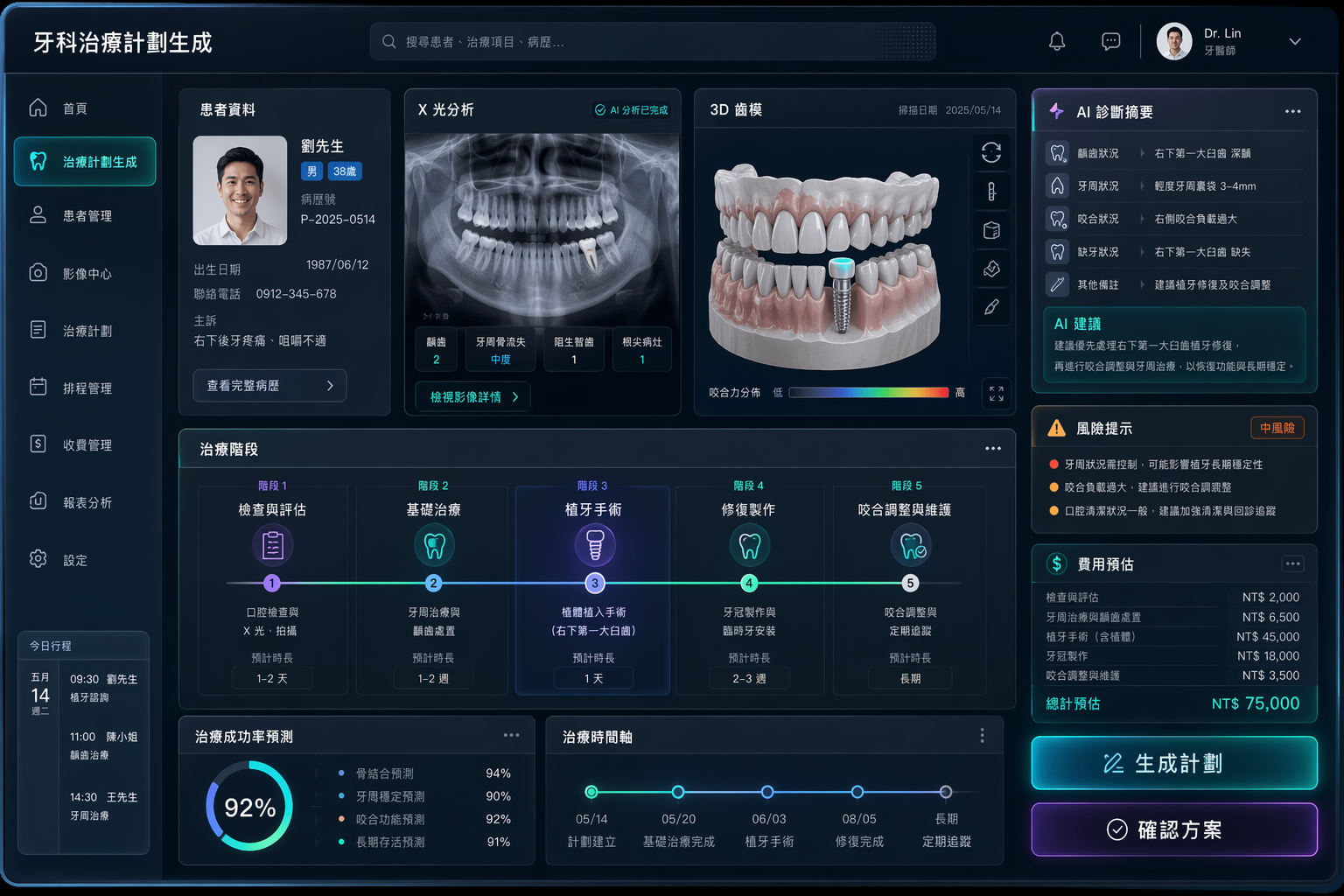
I tested two real cases on a dental theme — a treatment-plan generation UI and a patient education flyer. Both were essentially one-shot, with quality good enough to use. The UI is the cover image at the top of this article. The flyer looks like this:
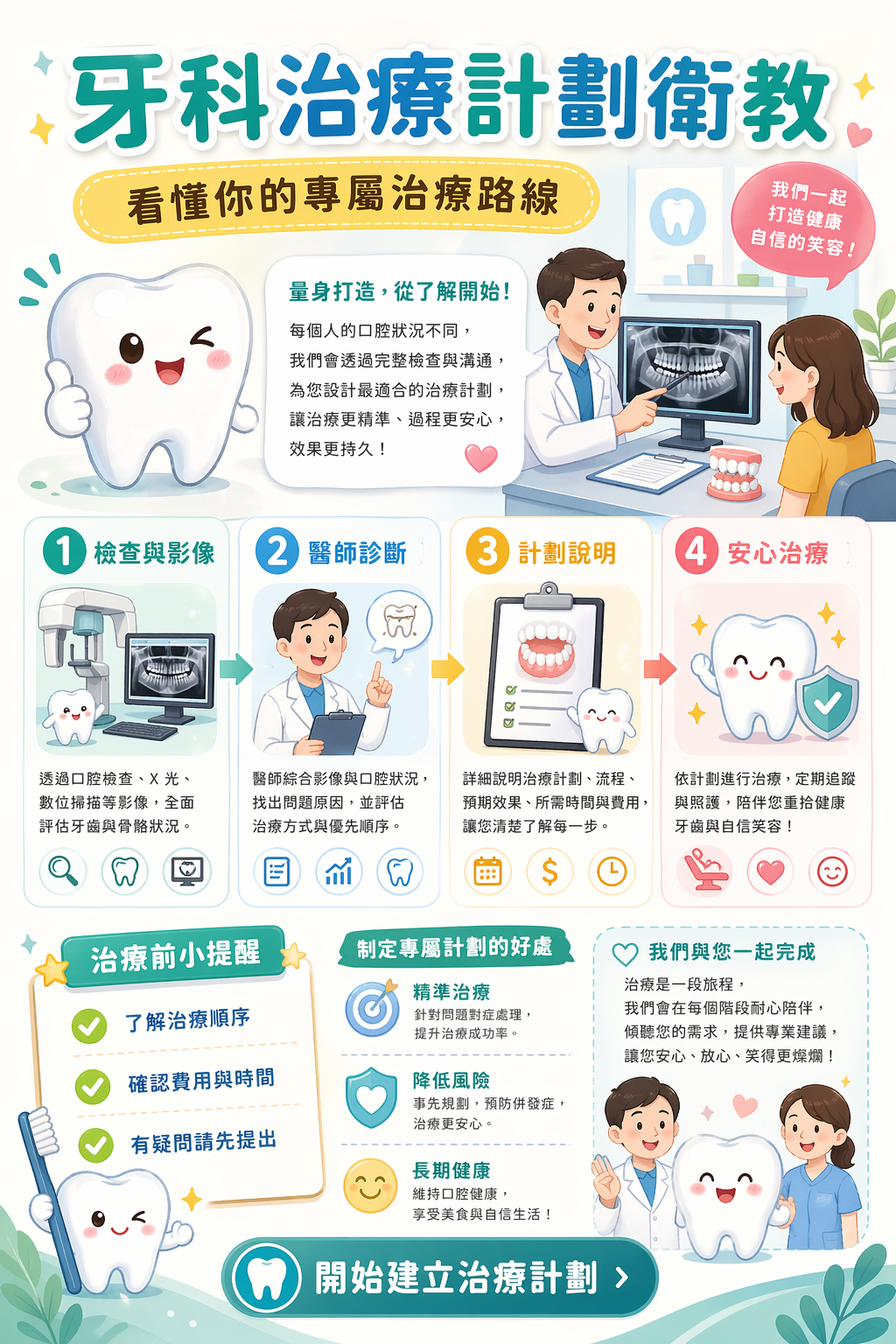
The Chinese text, the layout, the alignment, the visual style — all immediately usable. Worth trying yourself.
Next up I plan to write a more concrete SOP for adopting this pipeline inside a real project — prompt templates, agent handoffs, how team roles need to be redrawn.
PS
OpenAI also open-sourced Euphony today (a visualiser for ChatGPT conversations and Codex code structure). Anthropic must be feeling the pressure this week.


